
Open Targets Platform 26.06 has been released!
The latest release of the Platform —26.06 —is now available at platform.opentargets.org.
Key points
This release includes:
- Revamped baseline expression data, widgets, and target prioritisation views, now including PRIDE mass spectrometry proteomic data and single-cell RNA sequencing data allowing users to browse cell type-level data in addition to the existing tissue-level data.
- Data updates from several sources including the GWAS Catalog, plus an EFO update that replaces disease IDs with Mondo IDs.
- A number of updates to our data analysis pipelines: improving the accuracy of clinical mining, adding trans-pQTL features to Locus-to-Gene, and increasing the coverage and accuracy of our literature pipeline.
- Improvements to the Platform’s front-end: making the search function more flexible, adding URL sync, and increasing the accuracy of the subcellular location widget and drug molecule representation.
For the full list of updates, take a look at the release notes. For a list of key stats and metrics, please see the Open Targets Community.
Revamped baseline expression
We have added new sources and new types of data to our baseline expression information, with consequent updates to our target prioritisation view. Of note, we have added PRIDE mass spectrometry proteomic data and single-cell RNA sequencing data; the latter enables browsing cell type-level data in addition to the existing tissue-level data.
Sources of baseline expression data
The presence of a target molecule in a tissue or cell type of interest is critical information for drug development. Baseline RNA and protein expression data indicates where a target is expressed and whether it is broadly or selectively expressed.
We now have data from three different technologies from four sources:
- Single-cell RNA sequencing data from Tabula Sapiens
- Bulk RNA sequencing data from Genotype-Tissue Expression (GTEx) and the Database of Immune Cells (DICE)
- Mass spectrometry proteomics datasets from the PRoteomics IDEntifications Database (PRIDE), which was set up as part of an Open Targets project.
We aggregate donor-level data to produce a summary of expression for each target in each tissue or cell type.
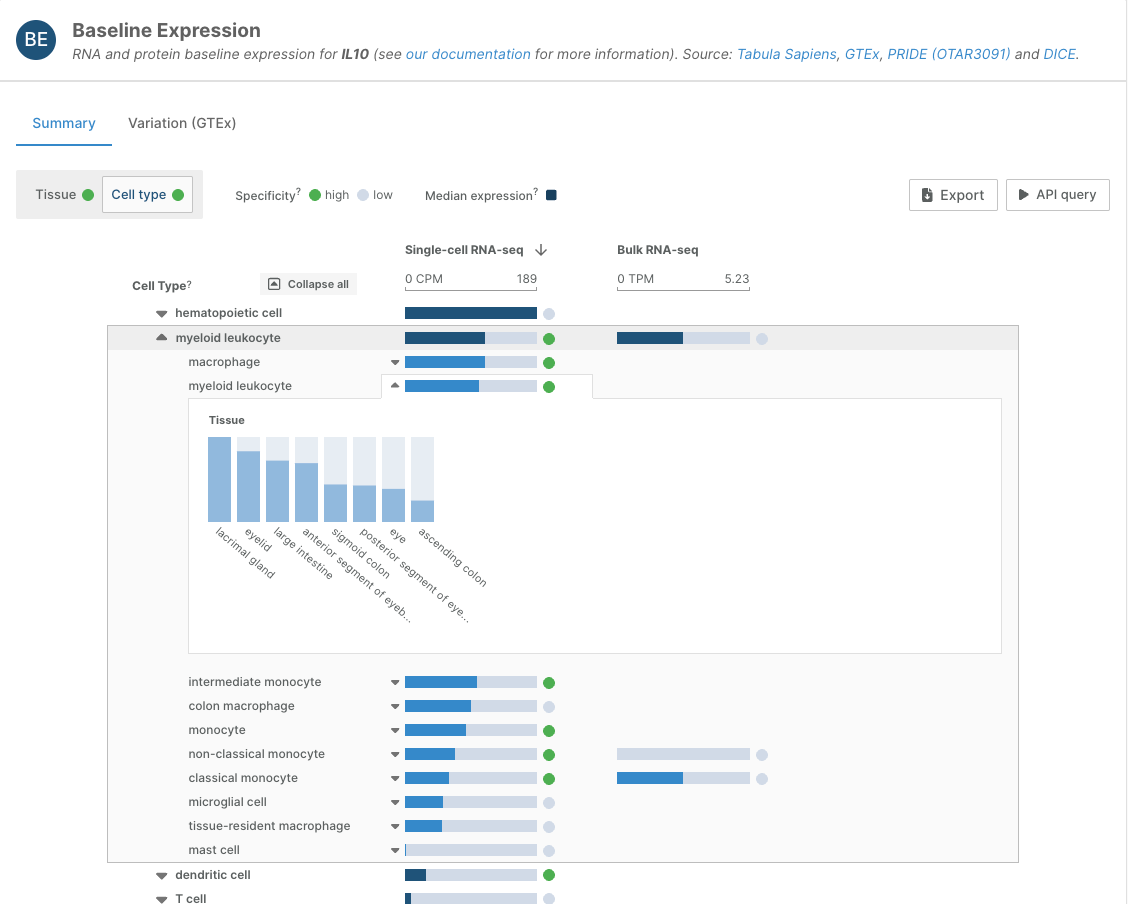
Find out more about the baseline expression data in our documentation.
Target prioritisation using baseline expression data
We have computed two sets of scores using the baseline expression data, replacing previous metrics: expression distribution scores and expression specificity scores. These replace the existing scores in our target prioritisation view, which now displays four scores for baseline expression: tissue distribution, cell type distribution, tissue specificity, and cell type specificity.
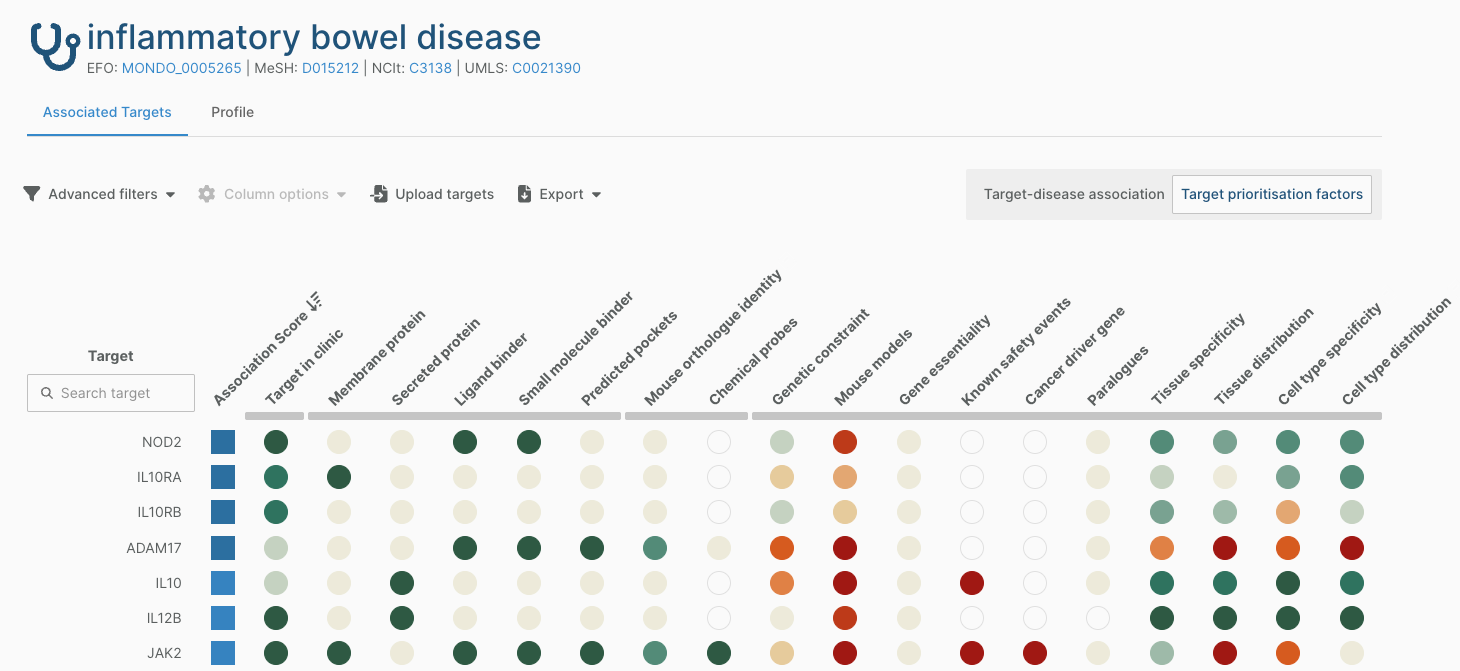
Expression distribution scores represent the breadth of expression within a dataset, defined as the proportion of annotations in which the target is expressed above a threshold. In the target prioritisation view, a score of 0 indicates ubiquitous expression.
Expression specificity scores are ranked specificity scores calculated using the CELLEX ESmu tool based on four specificity metrics. Specificity scores are relative: they reflect how specifically a gene is expressed in a given annotation (tissue/cell type) relative to all other annotations in that dataset.
Find out more about how we use baseline expression data for target prioritisation in our documentation.
Data updates
We have made a number of updates to the data in this release, including updating to ChEMBL 37, integrating a new panel from PanelApp NHSE Genomic Medicine Service, and ingesting new data from IMPC and ClinGen.
We have ingested the latest studies from the GWAS Catalog. This update integrates over 14,000 studies from 111 publications, adding a total of 27, 689 credible sets and over 105,000 new variants, including a global multi-ancestry study to identify genes and pathways associated with thyroid diseases (White SL et al. Nat Genet, 2026).
EFO 3.88 replaces EFO disease IDs with Mondo IDs
EFO 3.88.0 contains a mass replacement of EFO disease terms with Mondo terms. The Platform’s study and evidence mapping follows the change, so users shouldn’t notice differences unless they are searching for deprecated EFO terms directly.
Pipeline updates
Improved accuracy of our Clinical Mining pipeline
In our last release, we introduced a new clinical mining pipeline which pulls from additional data sources to improve the coverage and granularity of information about drugs and clinical candidates.
Most clinical reports link a drug to a disease. In some sources, this link is already structured and curated, whereas for others such as AACT, the link needs to be extracted from semi-structured trial metadata that often does not accurately represent the studied condition, which leads to false associations unless the trial is manually curated.
In this release, we have improved the accuracy of the data extraction from AACT by applying a Large Language Model (LLM)-based approach. The model reads the clinical trial descriptions and associated publications to extract information about the relationship, reducing false positives, and improving our list of drug synonyms.
For example, we are now capturing the linkage between Olaptesed Pegol, a CXCL12 inhibitor, and B cell lymphocytic leukaemia; providing clinical precedence for an association that was only supported by the literature.
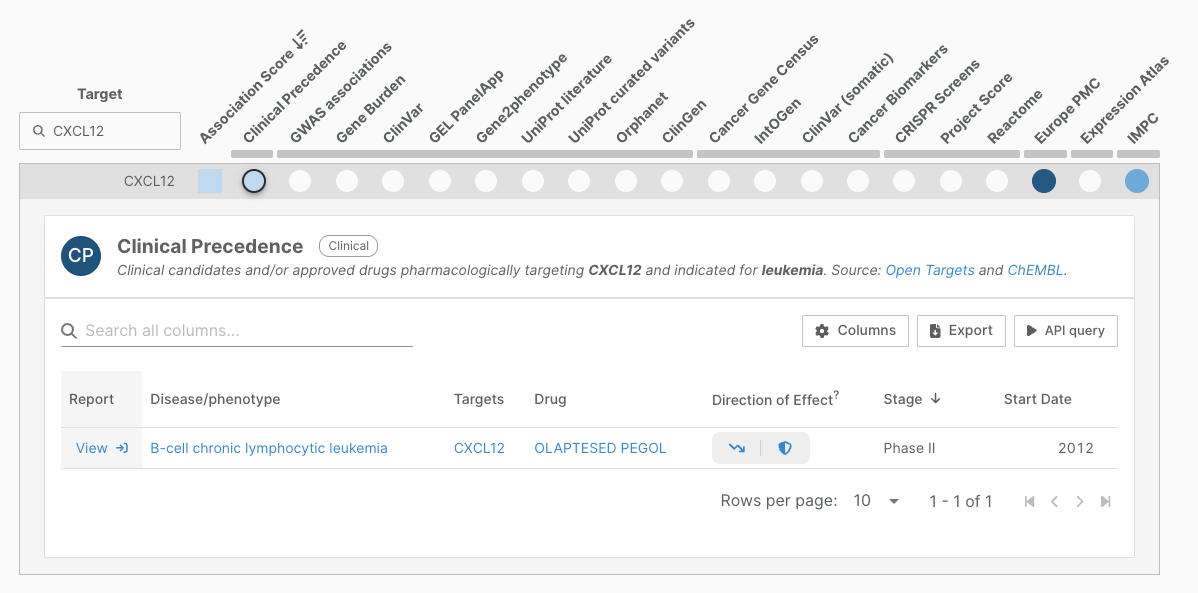
This update has added 4,742 additional clinical reports from AACT, 32,518 drug indication pairs, and 292,325 clinical precedence evidence.
Two trans-pQTL features added to L2G pipeline
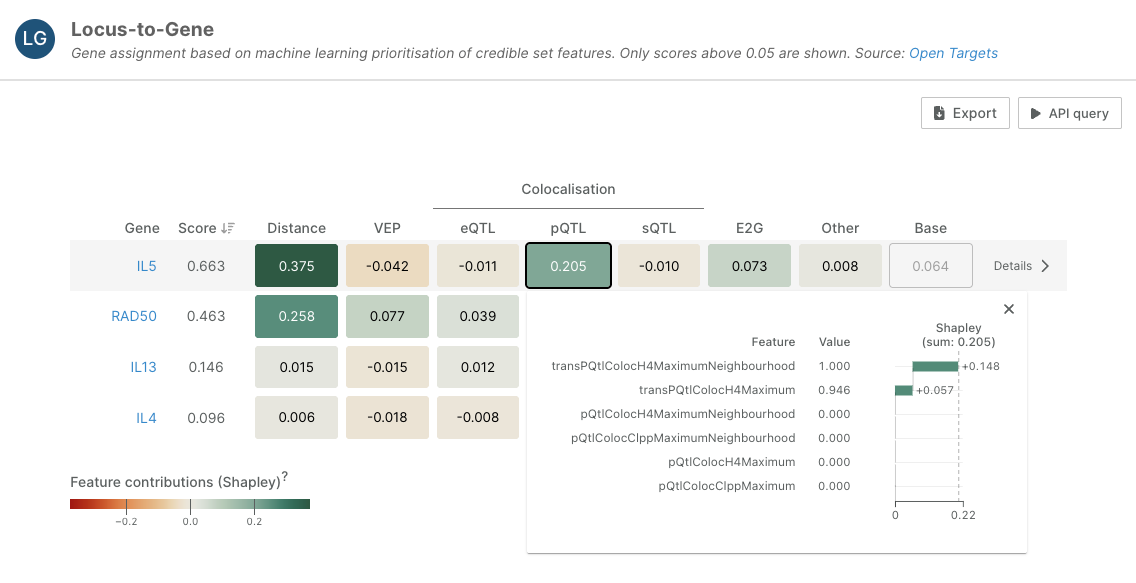
The Platform integrates two types of molecular QTLs: cis-QTLs, where the variant and molQTL gene are nearby, and trans-QTLs, where they are far apart, potentially even on different chromosomes. Our Locus-to-Gene (L2G) pipeline previously only used cis-QTLs, but evidence that a gene in trans interacts with a gene in cis increases our confidence that the cis signal is relevant.
Using our molecular interactions data, we have integrated two new pQTL features to the L2G pipeline: transPQtlColocH4Maximum, and transPQtlColocH4MaximumNeighbourhood. These features increase the coverage of functional genomics evidence, especially in cases where colocalisation with cis-pQTLs is not available.
For example, our Locus-to-Gene analysis now ranks IL5 as the most likely causal gene in a credible set derived from Karczewski KJ et al.’s study of asthma (Nat Genet, 2025). This prediction is supported by evidence from IL5RA acting in trans, and interestingly, the association is also clinically supported.
Revamping our literature pipeline
Our data team has been working to improve our literature mining pipeline.
- The code has been migrated from Scala to Python
- Entity grounding is now performed by OnToma, our Python package for ontology mapping.
- We have changed the way entity disambiguation is performed. Ambiguous entity mappings are now filtered in a more stringent manner to reduce false positives.
- The new processing pipeline also directly generates the co-occurrence dataset, which is now more comprehensive.
With these updates, 60,000 direct associations are no longer supported by literature evidence, due to the increased stringency of the disambiguation, but there is a net increase of 1.8 million literature evidence.
Software and front end updates
Search
We have made a number of updates to the Platform’s search capabilities. Users can now search for:
- Clinical trials using NCT IDs. Searching for a clinical trial will bring up the relevant drugs and indications connected with the study.
- Variants using a variety of separators for [CHR], [POS], [REF], [ALT] including dashes, underscores, colons, or a combination of these.
- Similarly, disease or ontology terms using a colon instead of an underscore (e.g. HP:0000822 or HP_0000822).
URL sync
The associations page URLs now retain complete state of the page. For example, if you make any adjustments to the scoring, add filters, pin targets, or open widgets, you can copy or bookmark the URL to come back to the page any time.
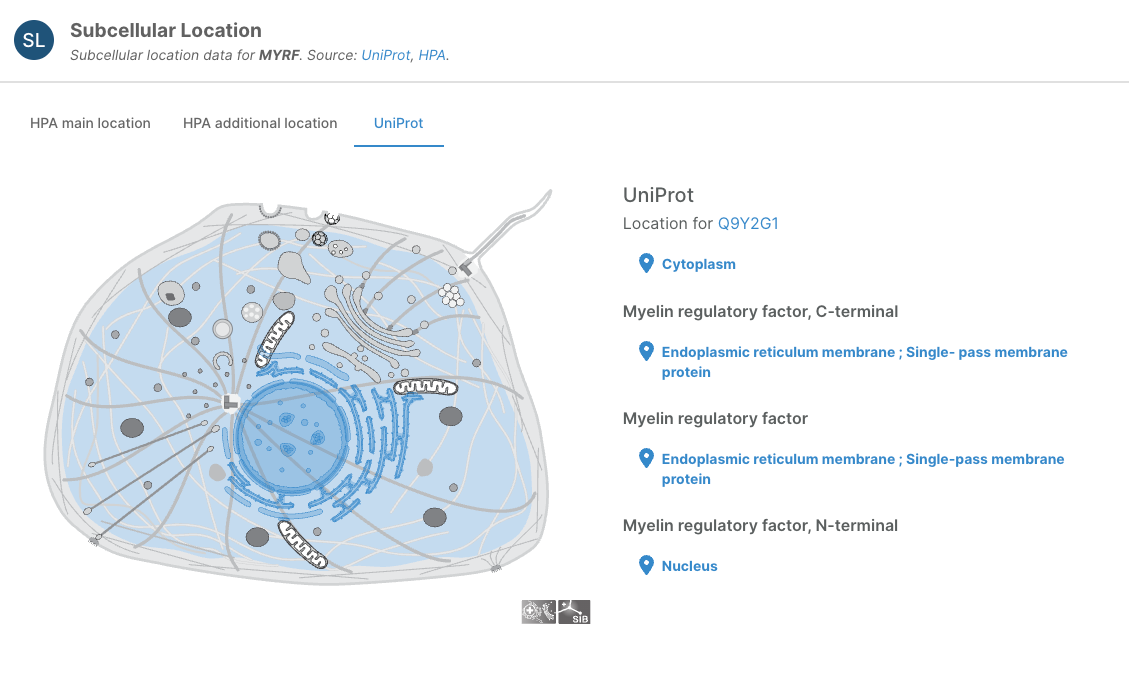
Subcellular location widget
We have improved the subcellular location widget to show isoform-specific subcellular localisation for UniProt sources.
This lets users see which subcellular localisation applies to which specific protein isoform. This matters for proteins where different isoforms have genuinely different locations (e.g. one isoform membrane-bound, another secreted or nuclear).
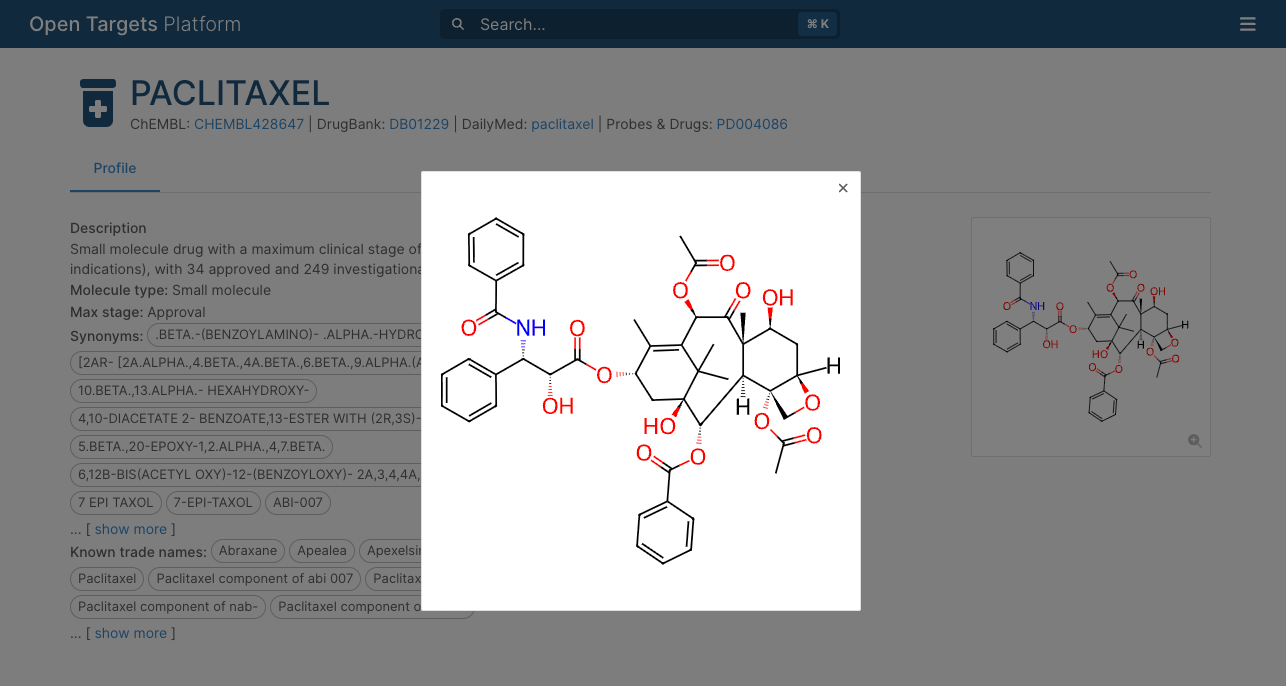
Drug molecule representation
We have replaced the molecule representations on our drug pages with more accurate ChEMBL images.
As usual, please share any comments, questions, or suggestions on the Open Targets Community.