
Open Targets Platform 21.02 has been released!
The latest release of the Open Targets Platform — 21.02 — is now available at https://www.targetvalidation.org/.
Our first release of 2021 includes a number of data updates from our external data providers and internal evidence generation pipelines. We have also updated our COVID-19 Target Prioritisation Tool and have a special announcement about the new version of the Platform coming later this year.
Key Stats
| Targets | Diseases | Evidence | Associations |
| 27,650 | 14,416 | 10,078,746 | 7,385,188 |
For more details, check out our /stats API endpoint.
Data updates
The 21.02 release integrates new data from:
- ChEMBL
- ClinGen
- Europe PMC
- EVA
- Gene2Phenotype
- PhenoDigm
- Reactome
- UniProt
Together with all of our other data sources, the Platform now has more than 10 million evidence strings that generate over 7.3 million target-disease associations.
New clinical trial records
In this release, we added more than 16,000 evidence strings from ChEMBL, allowing us to build new target-disease associations using records from ClinicalTrials.gov, DailyMed, and the US Food and Drug Administration (FDA).
Some of these new associations are based on various ongoing trials looking at investigational treatments for COVID-19. For example, based on the Phase II clinical trial with Fostamatinib, we now have an association between SYK and COVID-19. Fostamatinib is an approved small molecule targeting SYK, indicated for autoimmune thrombocytopenic purpura and hemorrhage, and currently being investigated as a treatment option for COVID-19 patients.
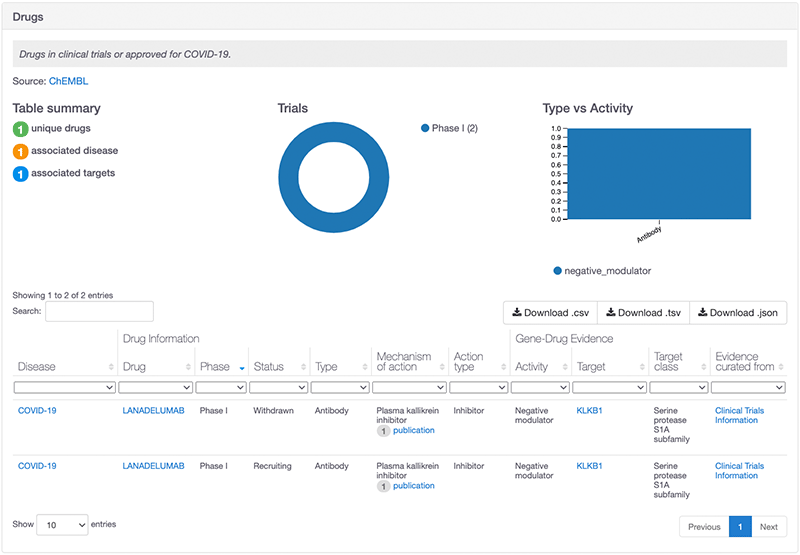
Another example of a new association: the association between KLKB1 and COVID-19 based on two Phase 1 clinical trials for Landelumab, a monoclonal antibody indicated for angioedema.
More ClinGen data
Last year, we introduce new evidence from ClinGen, integrating and scoring their Gene-Disease Validity Curations to add to our family of expert curated evidence sources.
And so for 21.02, we downloaded and integrated the latest ClinGen data, strengthening our target-disease associations, such as ANK2 and complex neurodevelopmental disorder and TMEM43 and arrhythmogenic right ventricular dysplasia 5.

The existing association between NBEA and complex neurodevelopmental disorder has been strengthened with "definitive" ClinGen evidence.
Updated PhenoDigm and Reactome data
To coincide with the IMPC 13.0 release, we reran our internal PhenoDigm data pipeline to gather evidence of target-disease relationships inferred from phenotypes in mouse models of disease, which are then mapped to phenotypes associated with human diseases. The Platform now features more than 717,000 animal model evidence strings, up from 687,000 in our previous release.
This has led to new associations and has strengthened existing ones, such as the association between PRG4 and rheumatoid arthritis.

The new association between IDS and rheumatoid arthritis based the latest PhenoDigm data
Similarly, we also integrated data from the latest Reactome release (version 75), which included new curations in the “Defective DNA double strand break response due to BARD1 loss of function” pathway.
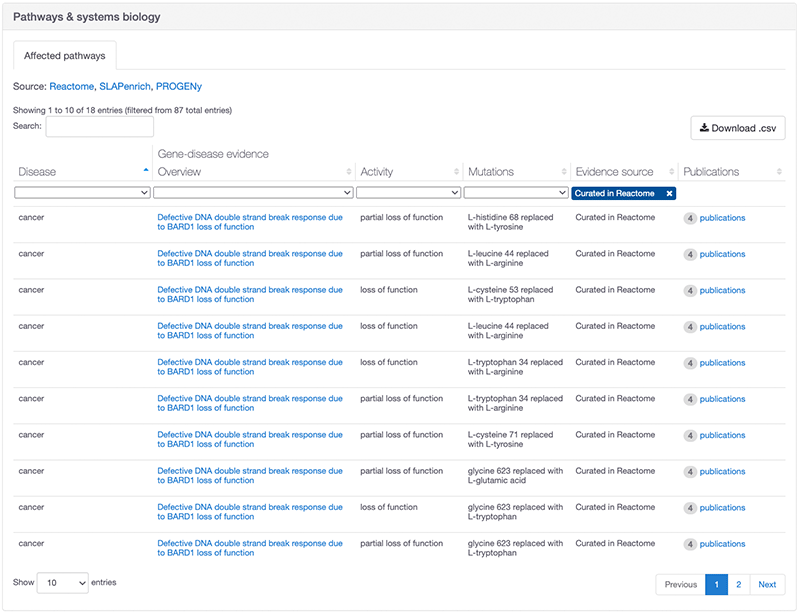
The BARD1 and cancer association with the latest Reactome data
Updated COVID-19 Target Prioritisation Tool
Using the latest data generated by our Platform pipeline, we also updated our COVID-19 Target Prioritisation tool. This tool includes a range of relevant data to help you systematically identify and prioritise potential COVID-19 targets and was featured in EMBL-EBI’s COVID response video.
You can now browse the information we have about the 1361 targets associated with COVID-19.
One of the new features we have implemented is the ability to sort for Mendelian Randomisation — the association between genetically predicted higher plasma concentrations of proteins with COVID-19 phenotypes, which can be used to predict the effect of drugs targeting these proteins.
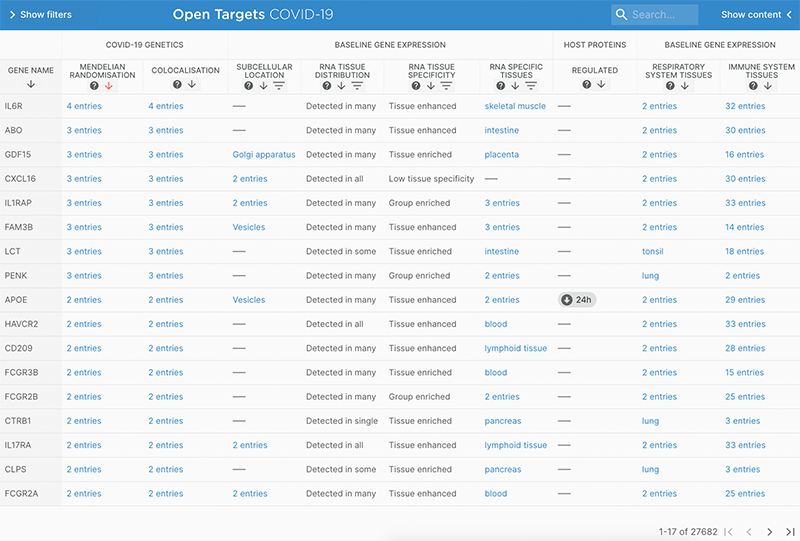
The tool contains data on more than 27,600 potential targets for COVID-19
Open data sharing is more important than ever, so please consider signing the European Bioinformatics Institute’s open letter in support of data sharing for Covid-19.
Get a sneak peek at the new Platform
As we have hinted in previous release posts, the Platform team is currently building a brand-new version of the Platform with new datasets and features, including a more powerful GraphQL API to support more complex data queries.
We are putting the final touches on our official Beta release but want to give you a sneak preview of what is coming at the end of the month.
One of the new features that you will immediately see in the Beta release is that each data source has its own section on our evidence page. This allows us to provide richer, source-specific evidence supporting the target-disease association.
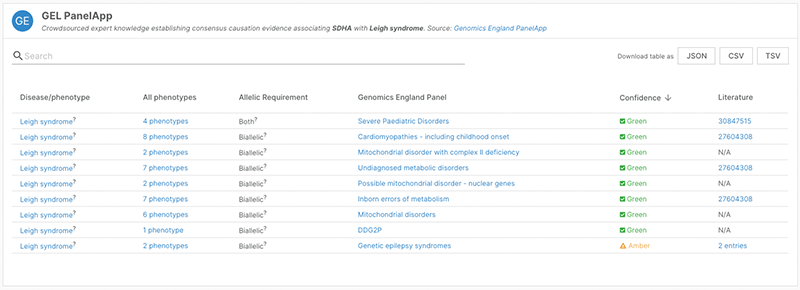
We now display the confidence, phenotype, allelic requirement, and panel data from Genomics England (example: SDHA and Leigh Syndrome).
To preview the Beta version before it officially launches later this month, visit https://beta.targetvalidation.org/.
And be sure to send your feedback about the Beta version to outreach@opentargets.org or complete the pop-up survey.


