How we improved our experimental data curation during the COVID-19 lockdown
A year after the COVID-19 pandemic first forced the Wellcome Sanger Institute, like many academic research institutes, to shut down our experimental programme, we reflect on how the Open Targets Community managed to keep their research progressing despite the challenges of lockdown.
With many of our colleagues unable to physically access the lab, we set up several community science projects that could be carried out virtually. These collaborative projects enabled us to harness the diverse expertise of our scientists and helped our researchers remain connected and scientifically active during this period.
We previously described a project that set out to improve clinical trial curation, which has made valuable contributions to the Open Targets Platform.
This time, we talk about a project in which researchers in the Open Targets community carried out a comprehensive literature search with a specific aim in mind: to capture valuable experimental information that will inform and shape our vision for large-scale experiments across Open Targets projects and in the Open Targets Validation Lab.
Here we share our approach and insights from this project, as well as the data capture template we have developed, in the hope that these will be valuable to other researchers undertaking similar projects.
Why was this needed?
Our mission at Open Targets is to leverage genetic and genomic information to systematically prioritise new disease targets, with the overarching aim of enabling the development of safe and effective medicines. We achieve this through the integration of informatic and experimental approaches to identify novel associations between genes and diseases.
Our efforts generate prioritised lists of potential drug targets, which subsequently undergo further experimental scrutiny that help us build additional evidence to support the relevance of the target in specific disease contexts. While aspects of target validation is a consideration in all Open Targets projects, the goal of the Open Targets Validation Lab is to develop systemic workflows that can be performed at scale.

Typically, a critical first step before committing to experimentation is to perform a detailed literature review of cellular assays that evaluate gene function in relevant disease models. However, this process is particularly time-consuming and challenging when the goal is to interrogate multiple genes simultaneously through the same functional readouts, a key requirement for the systematic validation and characterisation of targets.
Matching our volunteers with the scope of the project
Using the expertise of our volunteers, we focused on targets identified and prioritised within Open Targets, in two of our therapy areas: neurodegeneration, and immunity & inflammation.
Our volunteers in neuroscience were Kimberly Cheam, an advanced research assistant who is using cellular models to study IBD-associated risk genes, and Marta Perez-Alcantara, a postdoctoral fellow studying the effects of genetic variation in microglia on neurodegenerative diseases.
On the immunology side, we enlisted the help of Gareth Griffiths, a senior research assistant working on the regulation of CD4+ T cell activation, and Holly Robertson, a postdoctoral research fellow investigating the interaction between immune cells and tumours.
Establishing a data curation workflow
We started by identifying the key experimental information we wanted to capture and asked our volunteers to review the literature for the same well-validated and well-researched genes, for each disease indication; PLCG2 for neurodegeneration and CTLA4 for immunity & inflammation. Influenced by experimental concepts of reproducibility and use of positive controls, this approach enabled us to understand whether largely similar information could be captured by multiple independent searches and whether their output matched our benchmarks.
This task also helped us identify gaps in currently used experimental approaches. Therefore, we expanded our data collection to include key properties of the genes and proteins, such as expression pathways and associated phenotypes. This would help us to both optimise pre-established protocols for high-throughput experiments and develop novel assays.
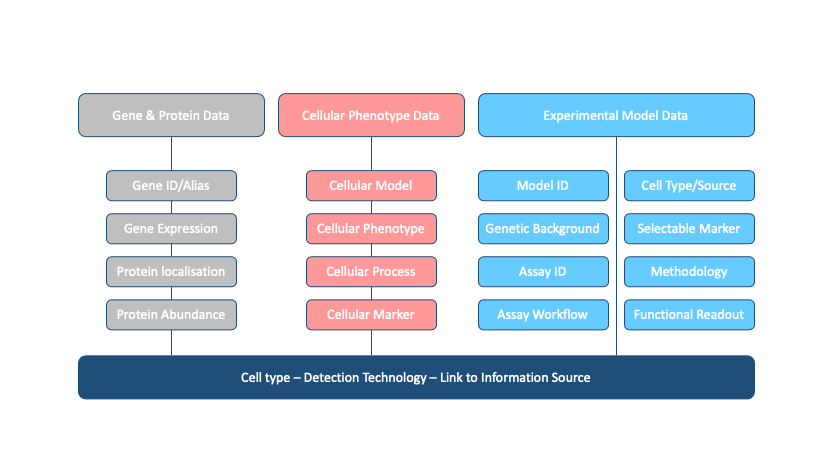
We finally chose sets of genes representing a mix of well- and under-studied prioritised targets, and allocated them to the volunteers based on their areas of expertise in order to capitalise on the volunteers’ background knowledge and to ensure that this exercise would be beneficial for their own research projects.
In a pilot phase each volunteer reviewed the information available for four genes. We then met with them to discuss findings, problems they had encountered, and to share tips with the group. Using this feedback we could further standardise and improve the process.
A few interesting points emerged from these discussions:
-
Beyond PubMed and other publication portals, a lot of very useful information was available through company websites, data repositories, or indeed simple Google searches;
-
Gene nomenclature was tricky for less researched genes, which was circumvented by use of the target profile pages and synonyms lists curated on our own Open Targets Platform;
-
Several targets were linked to cellular assays by association with the gene family, rather than being assayed directly within each experimental system.
Having optimised the information capture workflow, we fully rolled out the project and in addition to providing ad hoc support, we met monthly to provide feedback and allocate the next set of targets. The information capture portion of the project was completed in December 2020.
A first hand account from a volunteer: Gareth Griffiths

"As part of a Human Genetics research group, I work in immune genetics, looking at the mechanisms behind regulatory T cells in immune suppression. I’m predominantly a wet lab scientist, so working from home during the initial months of the pandemic was a new experience.
This project seemed like the opportunity to contribute to something worthwhile that would help the community. It’s been such a fantastic learning experience, and has really improved my understanding of gene pathways, protein interactions, and how it all fits together.
One of the hardest things was to limit the scope of my research. The sheer weight of data that’s been generated for some of these genes, especially in recent years, is immense. You could spend weeks just going through all the information available on some genes, so if you don’t limit yourself, you could fall down the rabbit hole.
There were a few things that surprised me. Gene nomenclatures have changed over time, which can make it difficult to find information about a certain gene. It can also be challenging when the function of genes was established a long time ago, because you have to work your way back to the original articles published in the 80s, for which there are often only digitised copies available.
I’m looking forward to seeing how this research informs the Open Targets experimental projects and the work of the Validation Lab."
What’s next?
Since the start of the project in May 2020, we have manually curated close to 30 genes within each disease area. The extension of national lockdown has also provided the opportunity for two of our Open Targets Senior Staff scientists Dr Sarah Cooper and Dr Carla Jones, with expertise in neurodegeneration and immunology respectively, to further review and benchmark the curated data against experimental workflows currently used in their labs.
The information capture template we created is now used for all our candidate targets, and the data captured in this project has already been used to inform approaches across our experimental programme. “The results of this project have been really helpful in our gene prioritisation efforts for the Open Targets neurodegeneration projects. Our post-docs have already been looking at the data collected by the volunteers to decide on candidate genes for the pilot single cell CRISPR screens and to decide on the best assays to set up,” explained Dr Sarah Cooper.
The experimental models and technologies we have identified, together with key genes that can be used as robust controls in these systems, show great potential in their compatibility to systematic, high-throughput phenotypic assay development. We are eager to soon start developing these underexplored functional readouts.
We have all found this process hugely useful and are grateful to our volunteers for their time and commitment to this project, while juggling their primary science activities.
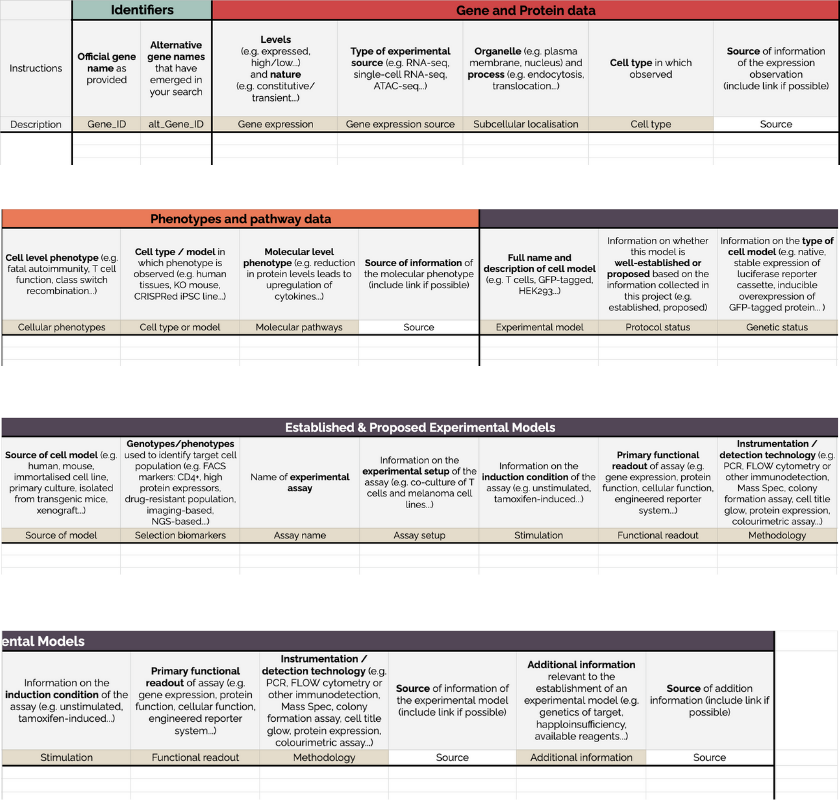
Our literature search template is available for you to use in your own research.
A BIG THANK YOU to all the volunteers who have contributed to our community project:
Holly Robertson (PostDoc, Sanger), Gareth Griffiths (Senior Research Assistant, Sanger), Kimberley Cheam (Advanced Research Assistant, Sanger), Marta Perez-Alcantara (PostDoc, Sanger), Sarah Cooper (Senior Staff Scientist, Sanger), Carla Jones (Senior Staff Scientist, Sanger)
Cover image by Samantha Hentosh on Unsplash