Designing the Perturbation Catalogue—a UX journey through perturbation data
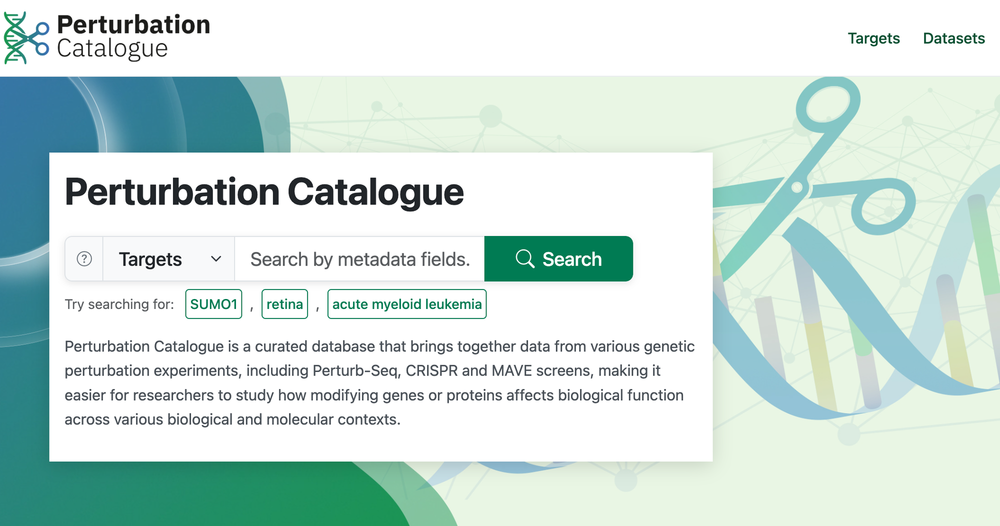
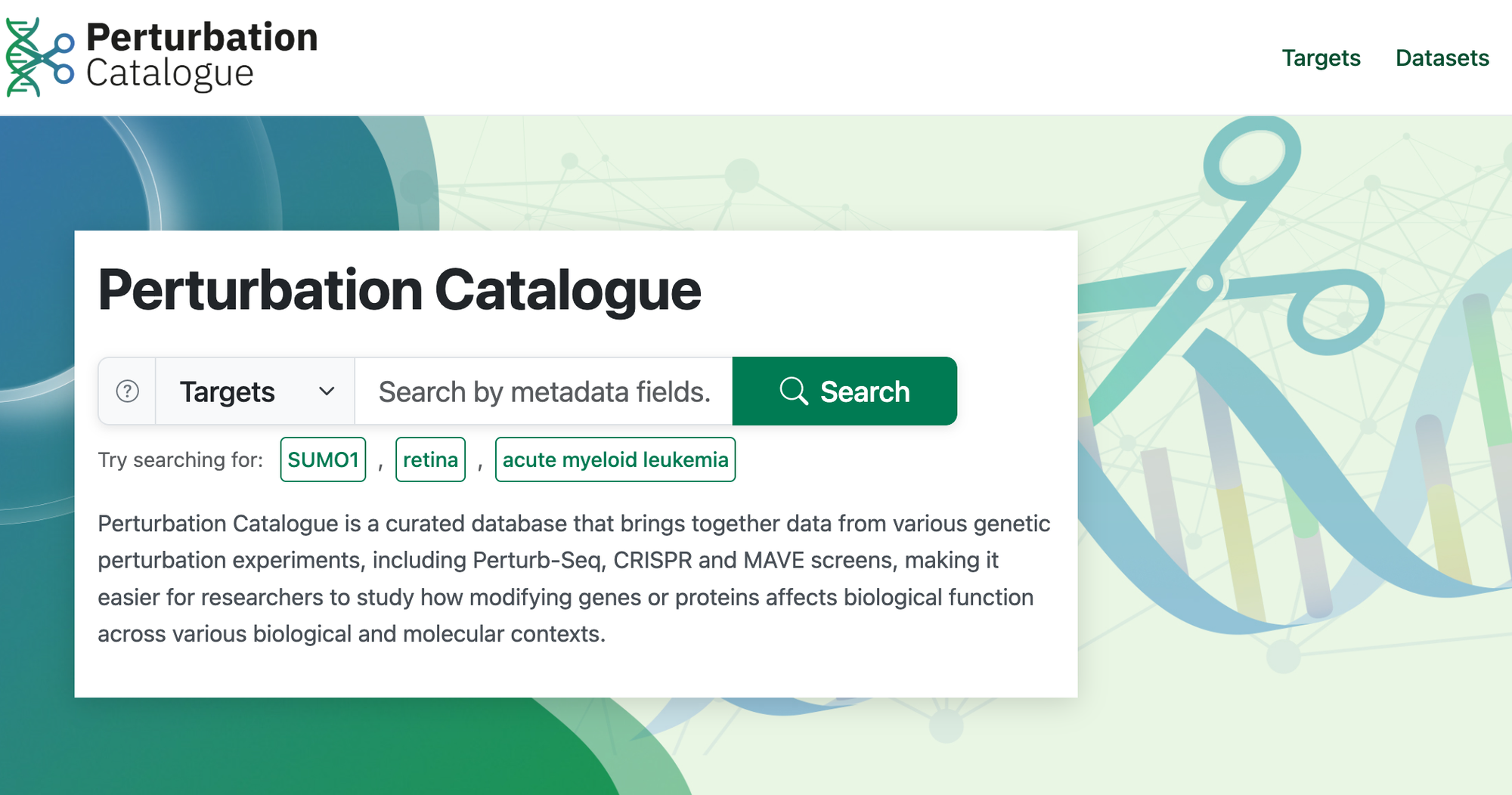
The Perturbation Catalogue is an Open Targets project that aims to bring genetic perturbation data into one curated, harmonised, and discoverable platform, hosted at EMBL-EBI.
With so much diverse and rapidly generated data, the team quickly encountered the challenges of curating and ingesting datasets under a common data model, often with sparse and heterogeneous metadata. But once the data is in, how do you ensure it's useful and structured in a way that answers the real questions of its scientific audience?
Thanks to collaboration with scientific teams at the neighbouring Wellcome Sanger Institute and Open Targets pharmaceutical partners, the project has actively sought feedback from key stakeholders and users from the very beginning. Shortly after the beta launch in July 2025, EMBL-EBI user experience experts Galabina Yordanova and Adedoyin Okunade were brought on board to steer user research and design activities, ensuring the project reflects genuine user needs.
We asked them to share how they crafted an intuitive experience for the Perturbation Catalogue through user research and iterative design.
Building a treasure trove of evidence
When we were invited to support the project team, we followed the four principles of the design process—Discover, Define, Develop, and Deliver—working with the resources available: a small but highly committed development team, and a community of scientists eager to access a resource like the Perturbation Catalogue.
During the Discover phase, we took every chance to speak with scientists who work with this type of data, applying different user research methods suited to each opportunity. After the beta portal launched in 2025, we ran focus group sessions with attendees of Ctrl+Alt+Del, an Open Targets discussion forum that brings together researchers working on genetic perturbation projects at the Wellcome Sanger Institute and EMBL-EBI. Our goal was to validate the top user journeys and goals using the very first datasets in the portal.
The feedback highlighted a clear need: a unified search experience with a single, intuitive entry point across heterogeneous data sources. Users wanted to compare results across studies and filter by different criteria. They also shared how they'd like to explore the data and which types of metadata mattered most—insights that would directly shape our search experience design.
"It would be beneficial if this data was provided in the context of tissue/model/organism."
"We want to be able to understand how individual gene/drug perturbations affect tissue expression profiles so that we can uncover regulatory networks and target pathways/multiple genes effectively."
These conversations and that first encounter with real data gave us the validation we needed to prioritise the key journeys and goals.

Focus on the top journey
With clear direction established, the team quickly generated design options for presenting the data, which were then tested through one-to-one usability sessions and A/B tests of two distinct design concepts.
Both proposals reflected what we'd learned about how researchers wanted to interact with the data. A series of brainstorming and analysis sessions with domain experts helped translate that complexity into a unified gene search journey—with the ability to filter rich, well-organised metadata in order of importance. We built these options rapidly as prototypes with enough functionality to generate meaningful feedback.
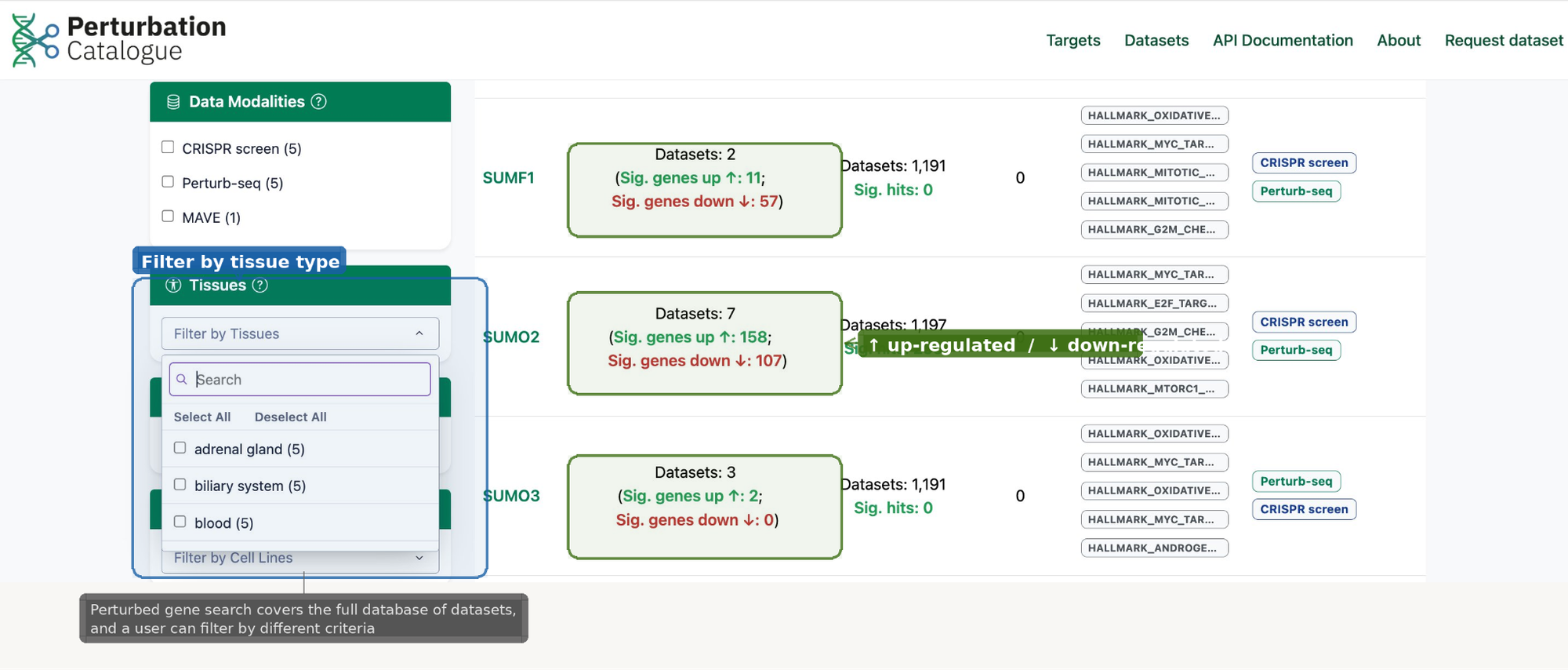
Both concepts clearly surfaced the target of interest regardless of data source, and showed the effect of perturbing that target on other genes. We also heard that researchers wanted a gene-centric page with different effect summaries, the ability to explore similar genes or genes within the same network or pathway, and to compare the effect of perturbation across genes.
Design, learn fast, improve
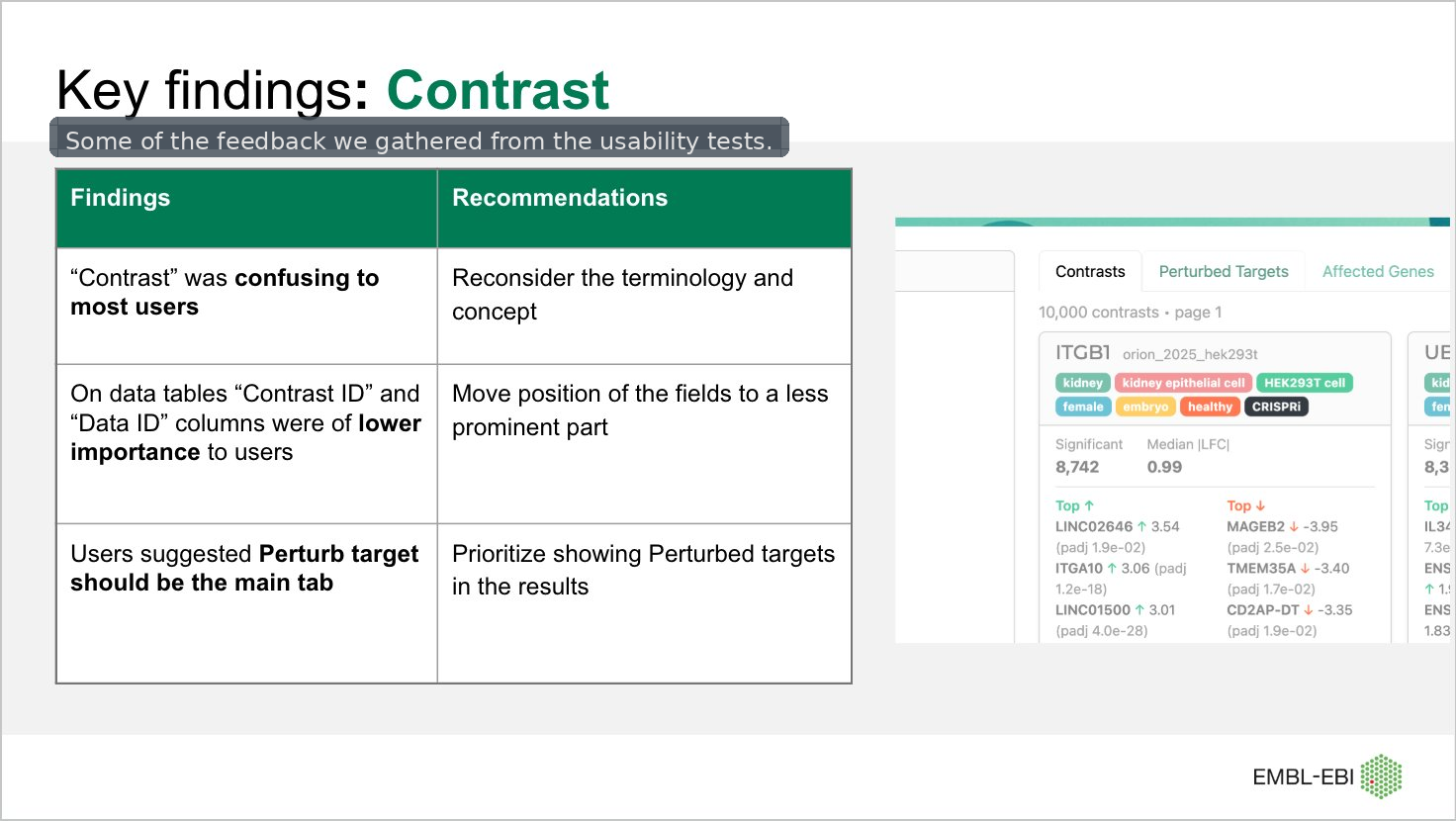
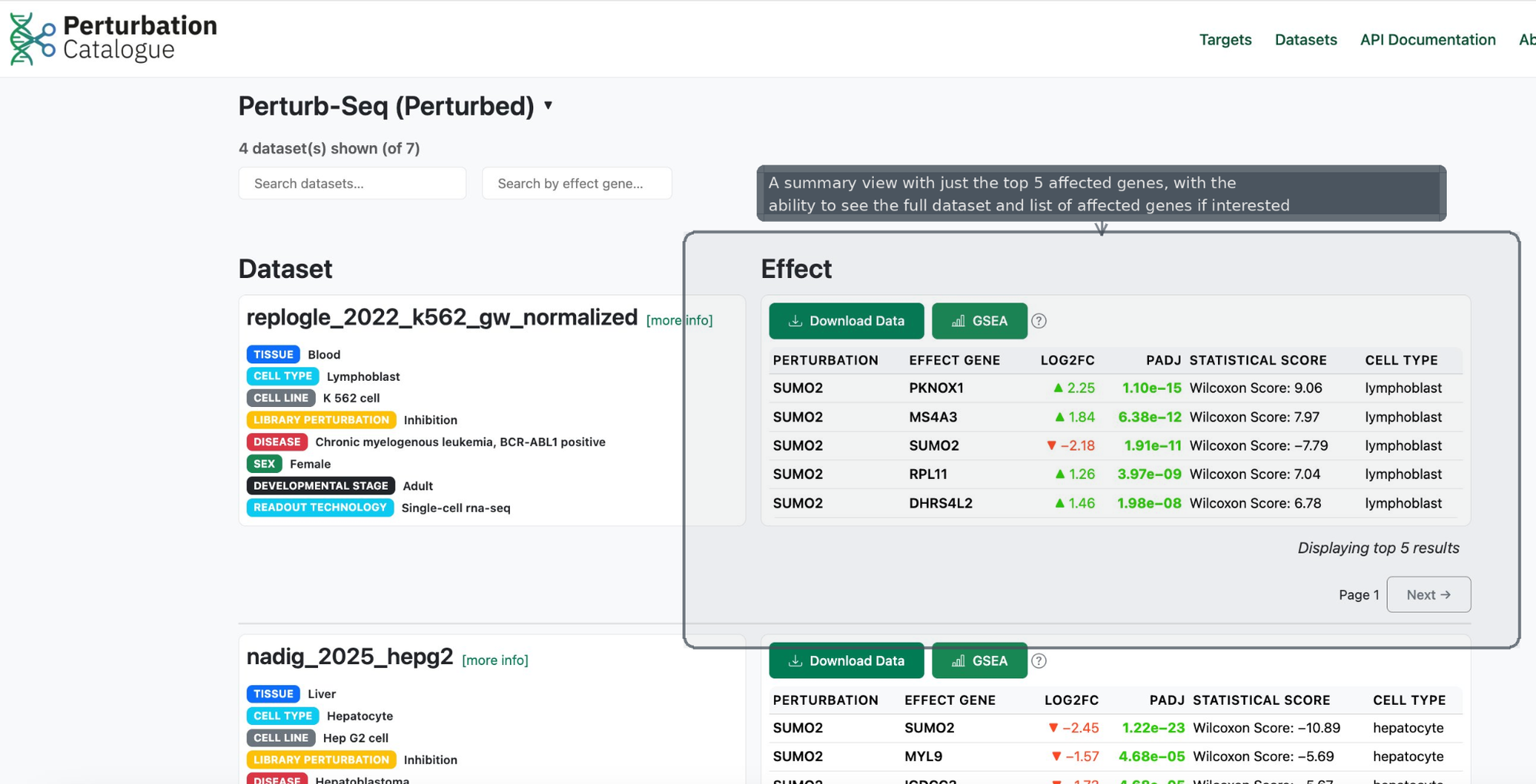
With these learnings, we continued the cycle of continuous feedback and iteration. We focused on surfacing the top perturbation summaries in results, while applying the principle of progressive disclosure to address information overload—showing only the most essential information upfront, and revealing further detail on specific gene pages. This kept the interface clean and uncluttered while still meeting core user needs. We also worked through several iterations of the naming conventions used across the portal to achieve maximum clarity.
Around this time, we delivered an expert accessibility and usability recommendations report to the team. This covered common accessibility standards (WCAG), improvements to information hierarchy, guidance on colour and contrast, and recommendations for descriptive content to support the various visualisations on the portal.
The Perturbation Catalogue now
The team has now launched a stable version of the data portal that supports the main user goals and journey. It is continually growing with new data, and the iterative feedback process has created a healthy backlog of features—including additional visualisation options and analysis descriptions, with increasing focus on individual gene pages.
We are also proud that the team has built a strong foundation of user experience knowledge and can continue this iterative cycle of gathering and acting on feedback. We look forward to continuing to support them as they build a robust, AI-ready infrastructure for this valuable data resource.
Design is a team sport
Collaboration was the primary driver of success throughout this project. Working closely with the product owner, developers, biocurators, and scientific stakeholders ensured that every design decision was grounded in both technical feasibility and domain knowledge.
Access to the people closest to the data—the scientists and their research questions—was invaluable in structuring complex information in a way that genuinely reflects their needs. We are also grateful that EMBL-EBI as an organisation values user experience and provides access to usability experts who can support development teams when needed.
Looking ahead, the Perturbation Catalogue is gaining real traction with researchers. It is a constantly evolving resource, and we look forward to seeing it grow with new functionality through continued user feedback. It stands as an example of how small, focused, expert teams can collaborate toward a common goal: helping scientists explore and make sense of this valuable data.
If you have feedback for the team, features or data you’d like to see integrated, please get in touch at: perturbation-catalogue-help@ebi.ac.uk