
Tutorial: Introducing the Open Targets Standalone Deployment Tool
Hello everyone! My name is Manuel Bernal Llinares, and I am the Technical Project Lead at Open Targets. I mentor, supervise, and work hand in hand with enthusiastic software engineers to bring our flagship target discovery platform to the life sciences community.
In this blog post, I will introduce a new standalone deployment tool we have developed for our internal processes. This tool positions Open Targets more firmly within the FAIR landscape.
This tool allows us (and you!) to deploy any Open Targets Platform release locally, anywhere, with the capability of replicating whatever Platform version we have released since March 2023, with just three commands:
# Select the release you want, e.g. 24.03
make set_profile profile='24.03'
# Launch the platform
make platform_up
# When you are done, tear it down
make platform_down
In this video, Manuel demonstrates the standalone deployment tool and lays out the main uses cases.
Explore additional use cases for this tool at the end of the blogpost
What are the FAIR principles?
FAIR stands for Findability, Accessibility, Interoperability, and Reuse. It is good practice to apply these principles to digital assets, now that we are relying more and more on computational support to deal with the increasing amount, complexity, and generation of data.
Find our more at go-fair.org
Open Targets release, behind the scenes
To give you a comprehensive understanding of what happens behind an Open Targets release, here’s an overview of our internal pipeline.
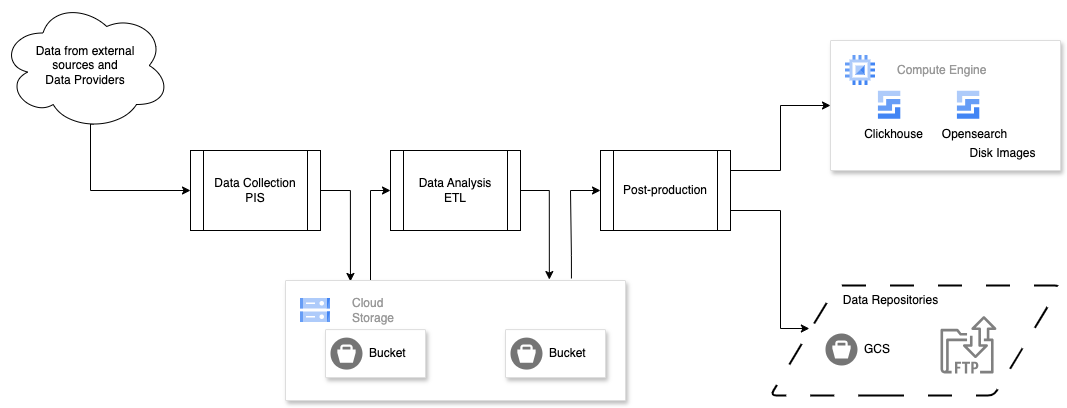
Open Target releases are data driven. Four times a year, we collect and process data to produce a result dataset that is packed together with software and delivered as an Open Target release.
This happens within our internal processes, through different stages, described below.
Data Collection
We gather data from various sources, which is detailed in my previous blog post on provenance metadata.
 Manuel Bernal Llinares
Manuel Bernal Llinares
Data Processing pipeline
Our ETL (Extract, Transform, Load) process aggregates and analyses these data sources. You can find more about our ETL process on GitHub.
The output from this pipeline is the data we use in the Open Targets Platform.
Platform data loading pipeline
The Platform implements a set of features / functionalities built on top of a sub-dataset of the ETL results.
Our POS (Platform Output Support) pipeline is in charge, among other things, of extracting and mapping data from ETL output to our platform.
Detailed information about POS can be found on GitHub.
Data and Platform release
Once the previous stages have completed, we release both data and Open Targets Platform to the community.
The data is made available via Google Cloud Storage and EMBL-EBI's FTP services; releases follow the year.month naming convention, 24.06 being the latest one (at the time of writing this post).
Open Targets Platform services are delivered via our Google Cloud infrastructure (see next section).
Open Targets Platform
In this section we'll have a high level view of the different elements that make the Platform, and how we deliver them via our cloud infrastructure.
Platform Architecture
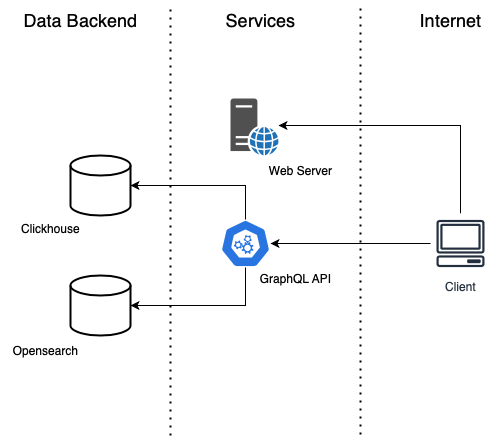
From a high level point of view, Open Targets Platform architecture consists of three key components:
- Data backend
- GraphQL API, provides a schema and mechanism to navigate the platform data for both programmatic access and our web frontend.
- Web Application: Our web frontend is the main entry point to our platform for most of the community, implementing a wide range of features that are of great value for our community.
Infrastructure
We use Google Cloud platform to run all our infrastructure, both for internal (e.g. pipelines, development environments, etc.) and external purposes.
Containerisation technologies (e.g. Docker) are used for running our services (API, Web, Opensearch and Clickhouse), and technologies like Terraform for defining all aspects of our Platform infrastructure as code.
Before March 2023, our data backends were running on machine images produced by POS where both software and data used to be packed together (although at least one of our data backends running the noSQL and search functionalities was already using Docker). Our relational backend still had a strong coupling between software and data.
Last year, we completed a big refactoring in our postproduction pipeline (POS), to decouple our data backend services from their underlying data representation, in a way that we can dynamically swap the underlying data for any of our SQL and noSQL data backends. In order to achieve this, our postproduction pipeline prepares data volumes that it plugs to Clickhouse and Openearch services for data loading, when the process is finished, these data volumes are shipped to our cloud infrastructure as:
- disk images, that we'll use in our machine templates as additional disks.
- tarballs, that are made available to the community as part of the data release.
Internally, we adapted our infrastructure as code machine definitions to use its corresponding additional disk for the data backend the machine is running, based on the produced disk images.
For external users, these data volumes can be found as tarballs within the disk_images folder as part of our data release, since March 2023. As an example, for the past release 24.03, they can be found in the following EBI FTP link
lftp ftp.ebi.ac.uk:/pub/databases/opentargets/platform/24.03> ls -al
drwxr-xr-x -- ..
drwxr-xr-x - 2024-03-20 17:05 conf
drwxr-xr-x - 2024-03-20 23:22 disk_images
drwxr-xr-x - 2024-03-20 18:08 input
drwxr-xr-x - 2024-03-20 18:25 jars
drwxr-xr-x - 2024-03-20 23:55 output
-rw-r--r-- 4.9M 2024-03-21 03:44 release_data_integrity
-rw-r--r-- 65 2024-03-21 03:44 release_data_integrity.sha1
drwxr-xr-x - 2024-03-20 23:55 sessions
drwxr-xr-x - 2024-03-20 23:55 webapp
## Data disks
lftp ftp.ebi.ac.uk:/pub/databases/opentargets/platform/24.03> ls -al disk_images
drwxr-xr-x -- ..
-rw-r--r-- 11G 2024-03-05 18:16 clickhouse.tgz
-rw-r--r-- 28G 2024-03-05 19:11 elastic_search.tgz
Decoupling the data from the services running on it allowed us to develop our Standalone deployment tool for Open Targets Platform.
Standalone deployment tool
This tool is both an internal tool and a way to showcase the community how to use our data volumes by deploying a full Open Targets Platform locally anywhere, with the capability of replicating whatever Platform version (as far back as March 2023) we've released.
This tool can be found on GitHub, as part of our open source codebase.
An Open Targets Platform release is defined as a collection of software, data images and some operational configuration. All these elements are collected together in a Deployment Context as part of our infrastructure definition, within the profiles folder.
As an example, the following is an excerpt from our 24.03 release deployment context.
// --- PRODUCTION Open Targets Platform ---//
// --- Release Specific Information (THIS IS THE MAIN PLACE WHERE THINGS CHANGE BETWEEN PRODUCTION RELEASES) --- //
// --- Elastic Search configuration --- //
config_vm_elastic_search_data_volume_image = "posdevpf-20240305-1702-es"
// --- Clickhouse configuration --- //
config_vm_clickhouse_data_volume_image = "posdevpf-20240305-1702-ch"
// --- API configuration --- //
config_vm_platform_api_image_version = "24.0.3"
// --- OpenAI API configuration --- //
config_openai_api_docker_image_version = "0.0.10"
// --- Web App configuration --- //
config_webapp_release = "v0.7.11"
// Web App Data Context
config_webapp_bucket_name_data_assets = "open-targets-pre-data-releases"
// -[END]- Release Specific Information --- //
Where:
- config_vm_elastic_search_data_volume_image defines the data volume image used for our Opensearch backend
- config_vm_clickhouse_data_volume_image defines the data volume image used for our Clickhouse backend
- config_vm_platform_api_image_version specifies the GraphQL API version being deployed
- config_openai_api_docker_image_version this defines which version of our OpenAI API to deploy
- config_webapp_release defines which version of the web application is part of the Platform release being defined
While this deployment context is used within our infrastructure as code to put together the elements that constitute our platform, our standalone deployment tool implements a similar concept, there is a collection of configuration profiles within the profiles folder.
Given our our 24.03 release deployment context, this is how the equivalent configuration file would look like for our standalone deployment tool.
#!/bin/bash
export OTOPS_PROFILE_DATA_RELEASE=24.03
# -- Clickhouse -- #
export OTOPS_PROFILE_CLICKHOUSE_DOCKER_IMAGE_NAME=clickhouse/clickhouse-server
export OTOPS_PROFILE_CLICKHOUSE_DOCKER_IMAGE_TAG=23.3.1.2823
export OTOPS_PROFILE_CLICKHOUSE_DATA_SOURCE="https://ftp.ebi.ac.uk/pub/databases/opentargets/platform/${OTOPS_PROFILE_DATA_RELEASE}/disk_images/clickhouse.tgz"
# -- Elastic Search -- #
export OTOPS_PROFILE_ELASTIC_SEARCH_DOCKER_IMAGE_NAME=docker.elastic.co/elasticsearch/elasticsearch-oss
export OTOPS_PROFILE_ELASTIC_SEARCH_DOCKER_IMAGE_TAG=7.10.2
export OTOPS_PROFILE_ELASTIC_SEARCH_DATA_SOURCE="https://ftp.ebi.ac.uk/pub/databases/opentargets/platform/${OTOPS_PROFILE_DATA_RELEASE}/disk_images/elastic_search.tgz"
# -- API -- #
export OTOPS_PROFILE_API_DOCKER_IMAGE_NAME=quay.io/opentargets/platform-api
export OTOPS_PROFILE_API_DOCKER_IMAGE_TAG=24.0.3
# -- OpenAI API -- #
export OTOPS_PROFILE_OPENAI_API_DOCKER_IMAGE_NAME=quay.io/opentargets/ot-ai-api
export OTOPS_PROFILE_OPENAI_API_DOCKER_IMAGE_TAG=0.0.10
export OTOPS_PROFILE_OPENAI_TOKEN=$OPEN_AI_SECRET_KEY
# -- Web App -- #
export OTOPS_PROFILE_WEBAPP_RELEASE=v0.7.11
export OTOPS_PROFILE_NGINX_DOCKER_IMAGE_NAME=macbre/nginx-http3
export OTOPS_PROFILE_NGINX_DOCKER_IMAGE_TAG=1.21.3
export OTOPS_PROFILE_WEBAPP_BUNDLE="https://github.com/opentargets/ot-ui-apps/releases/download/${OTOPS_PROFILE_WEBAPP_RELEASE}/bundle-platform.tgz"
The most relevant parameters in our configuration file are:
- OTOPS_PROFILE_DATA_RELEASE, this is the release name, usually year.month.
- OTOPS_PROFILE_API_DOCKER_IMAGE_TAG, it defines the version of our GraphQL API to be used in the deployment.
- OTOPS_PROFILE_OPENAI_API_DOCKER_IMAGE_TAG, which version of our OpenAI API to deploy.
- OTOPS_PROFILE_WEBAPP_RELEASE, this defines which version of our web frontend to use in this deployment.
Once the configuration profile has been set with all the values from the release we want to deploy locally, we can use the tool to deploy the Platform.
A Makefile helper is the command line interface for the tool. Given the configuration profile name '2403', we would launch the Platform following these commands sequence:
# Activate the configuration profile
make set_profile profile='2403'
# Launch the platform
make platform_up
What is happening behind the scenes?
- Data tarballs are downloaded from our EMBL-EBI FTP data repository.
- A web bundle is downloaded from GitHub matching the web application release version set in the configuration file, and prepared locally for this deployment.
- Docker-compose is used to bring the software side of things up and running, this includes Clickhouse, Opensearch, the platform GraphQL API, the OpenAI API and a Web Server for the frontend.
Once it's all up, point your browser to http://localhost:8080 for the web frontend, or http://localhost:8090 for the GraphQL API.
Once you no longer want to keep using this locally deployed instance of Open Targets Platform, just use the following command to tear everything down.
make platform_down
That's it!

Further use cases
In this post we introduce a new tool to create local portable deployments of Open Targets Platform releases, but not limited to the context of a release, as well as the journey of changes that made the creation of this tool possible.
This new approach to data and software in our Platform unlocks additional degrees of freedom that are of great benefit for the community, and it enhances our FAIRness score:
- Platform reproducibility; other parties can deploy an exact copy of any of our releases back to March 2023.
- It makes it possible to run several versions of the Platform at the same time, e.g. for side by side comparisons.
- It provides an easy mechanism of swapping data backends and components, which speeds up and eases components integration.
- It helps our team in deep dive investigation of some bugs on their local machine for which it's difficult to find the underlying cause.
- It can be embedded in development environments for components like our GraphQL API.
- It simplifies the prototyping and development of proofs-of-concepts for users who want to integrate additional data into the Platform, for example internal or private datasets. It provides immediate feedback on how the new data would affect the functionalities of the web interface and the GraphQL API in the Platform.
- Similarly, we have found when developing new components to be integrated in the Platform ecosystem, this tools improves the development cycle by providing real time immediate feedback on their interaction with existing Platform components.
- It offers help on profiling our Platform services and data models.
- And it enables the creation of autonomous isolated Open Targets Platform deployments, e.g. for air gapped environments where connection to the internet is not allowed or where an internet connection is not available, increasing global accessibility to our resource.
As well as for members of our team, and companies that have an internal version of the Platform and want to test new data or tools, we hope this tool will also be very useful for training the next generation of software developers/engineers/data scientists/web developers.


