The next-generation Open Targets Platform: rebuilt, redesigned, reimagined
The next-generation version of the Open Targets Platform — the culmination of two years of work — is now officially live! It replaces our previous version, with a fresh new look, brand new features, and streamlined processes.
It is available at platform.opentargets.org.
Please note, we will no longer be using the targetvalidation.org url, to bring the Platform in line with our other informatics tools.
The release of this next-gen Platform coincides with our latest data release — 21.04 — and so includes the most up-to-date information from our data providers.
We have also rewritten and streamlined the accompanying documentation, which now provides more in-depth information on the data and the methods we use.
Finally, we have created a community forum to host discussions and foster collaborations among users. It will feature the latest updates from the Platform, and provide technical support. Join the Open Targets Community now at community.opentargets.org.
In a nutshell
-
The new design of the Platform improves user experience and access to information. It has been reimagined to facilitate the building of new therapeutic hypotheses;
-
New features include data on binary molecular interactions, and black box warnings;
-
A complete refactoring of the codebase enables rapid development and new deployment strategies.
New data and approaches
Significant increase in target-disease evidence
With the latest data release (21.04), the Platform now features:
| Targets | Diseases | Evidence Strings | Associations |
| 29,293 | 14,413 | 13,648,521 | 9,452,623 |
As part of our project-wide rewrite efforts, we have completely overhauled our evidence data model. We have a new data schema that is flatter and more streamlined, allowing for much more efficient analysis of the evidence across different data sources.
The new evidence model also makes it easier to incorporate your own data if you run a private instance of the Platform.
New data on binary molecular interactions
The Platform now includes a widget for molecular interaction data, through an Open Targets collaboration with the European Bioinformatics Institute’s Intact database.
Genes and proteins that interact with each other typically work together in the same processes, and are therefore more likely to be associated in disease. Molecular interactions can indicate other potentially relevant targets, or increase the confidence in a given target.
Our pipeline integrates different pairwise interactions — physical, regulatory, functional — between the selected target and all other human or pathogenic (e.g. SARS-CoV2) proteins and RNA molecules.
We display interaction data from four sources:
These sources differ in how they represent interactions, and so are displayed separately.
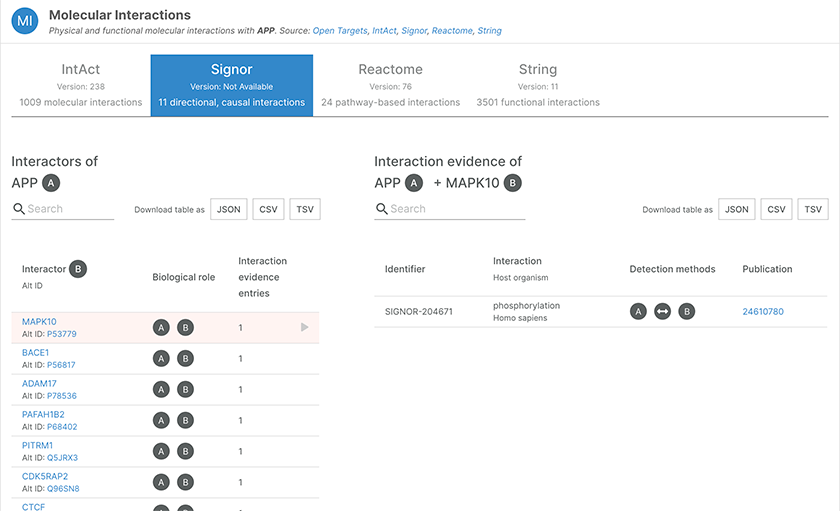
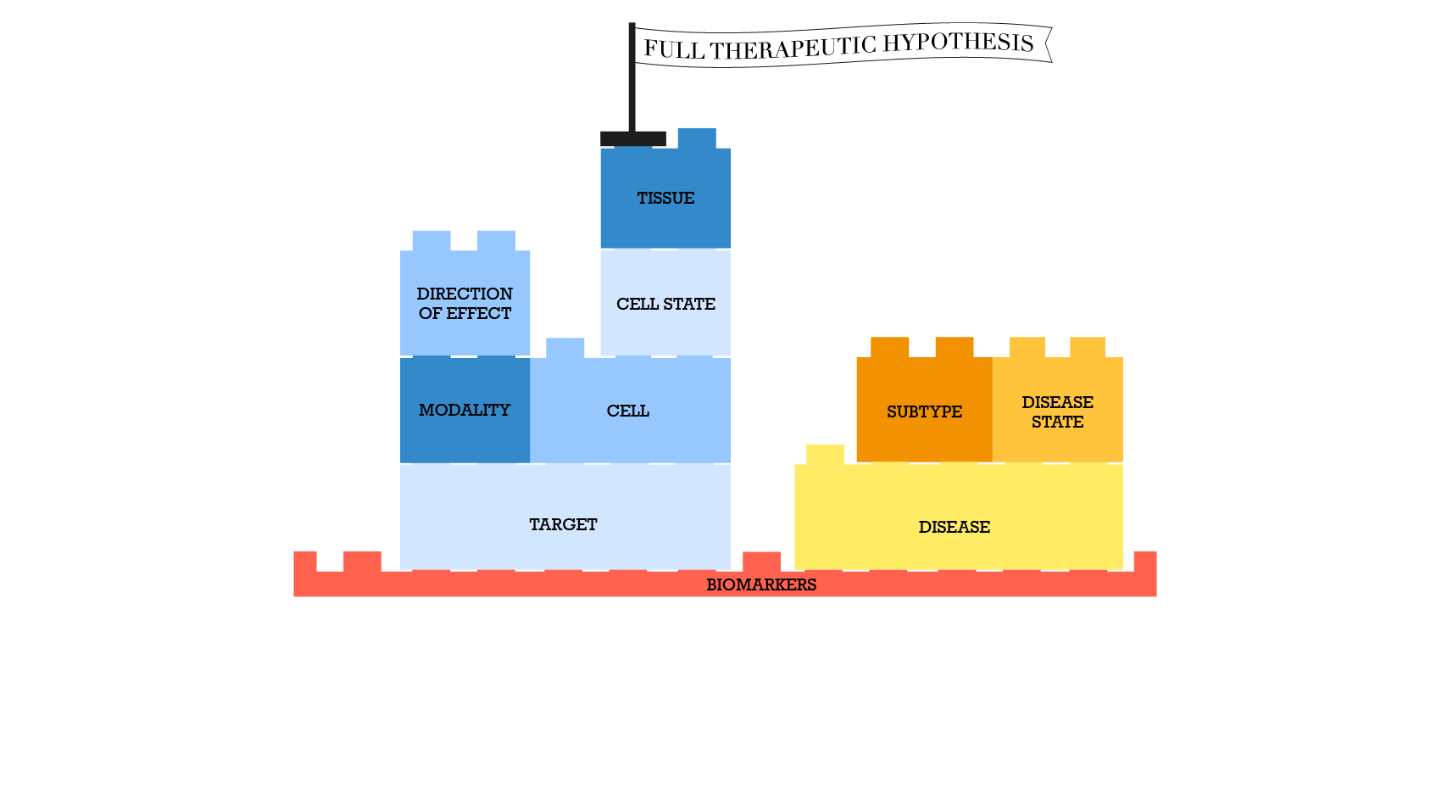
The molecular interactions widget for the Amyloid beta Precursor Protein, showing the directional, causal interactions retrieved from Signor.
Users can explore the underlying evidence for each interaction with our new GraphQL API, including references to the original publications, and/or the interaction detection method. The data is also available to download.
Black box warnings and drug withdrawals
A black box warning, or boxed warning, is the FDA’s most severe warning for drugs on the market, indicating serious side effects such as injury or death.
Thanks to work from our colleagues at ChEMBL, this information is now available in the Open Targets Platform.
“Our recent work has classified the type of adverse effect described in boxed warnings on a per drug basis. For medicinal products that contain one active pharmaceutical ingredient, a boxed warning can be directly linked to a drug. Therefore, toxicity class(es) have been assigned to approved drugs with boxed warning information described on medicinal product labels (e.g. cardiotoxicity, hepatotoxicity, etc).”
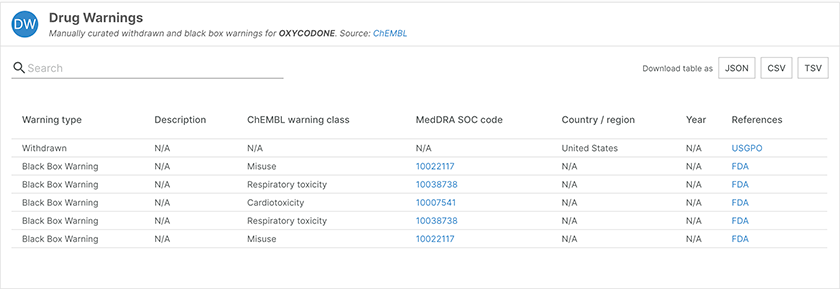
The Drug Warnings widget for oxycodone, showing drug withdrawal and warnings for misuse, respiratory toxicity, and cardiotoxicity.
Find out more in the related publication or in ChEMBL’s accompanying blog post.
A completely new literature-mining strategy
An Open Targets project in collaboration with Europe PubMedCentral has created a new literature-mining strategy using natural language processing.
Our new pipeline uses a deep learning method (a BioBert-based trained algorithm) for named entity recognition and reports sentence level matches of our 3 main entities — targets, diseases and drugs. The recognised tags are then grounded using the Open Targets Platform reference identifiers accounting for all synonyms or alternative names. The resulting entity occurrences in literature are presented in the bibliography widget, as well as for the literature mining evidence based on target-disease co-occurrence.
New algorithms to explore entities
We have implemented new algorithms to explore the universe of entities and their similarities in the literature. This allows us to display significantly more relevant publications, and enables users to explore different entities mentioned similarly in the literature.
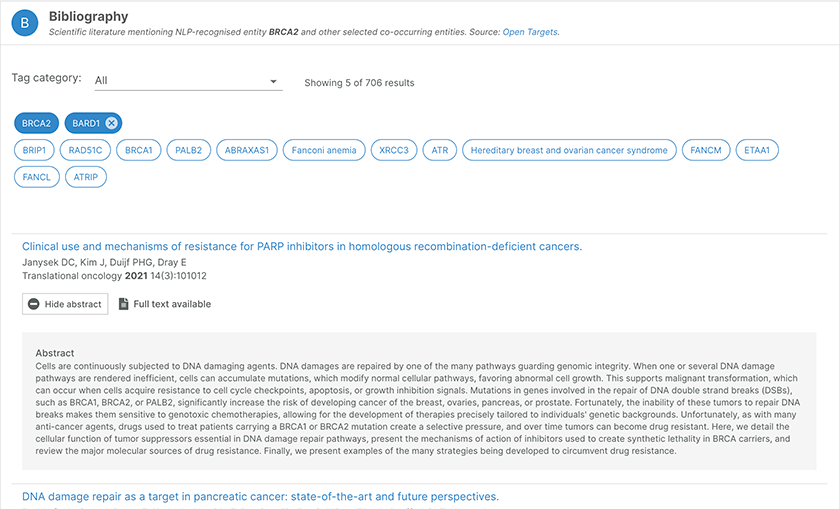
The literature widget for BRAC2.
The co-occurring entities can be filtered for targets, diseases, or drugs. Selecting an entity, such as BARD1 in the above example, will bring up a list of publications in which BRAC2 co-occurs with BARD1. Users can read the abstracts of these publications, or click out of the Platform to read the articles.
Other new features
- We have made literature sources easier to navigate. Clicking a reference number in one of the widgets will bring up our new publications drawer, which displays the full reference and the abstract for the selected publication, and indicates whether the full text is available.
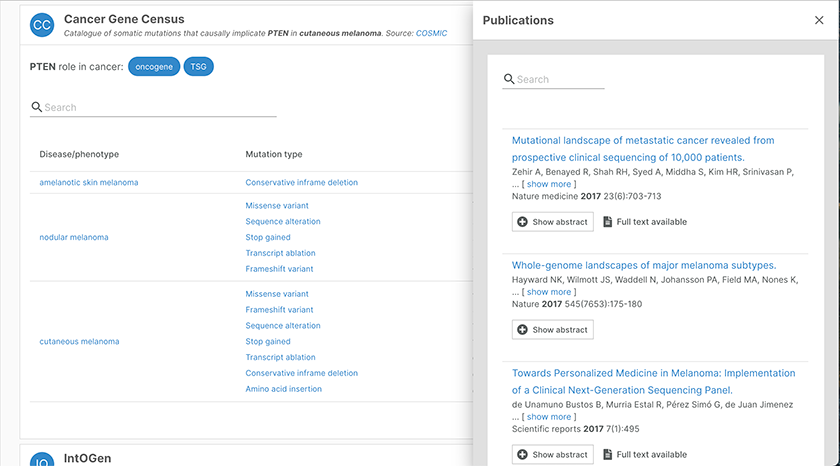
Clicking on the references for a piece of evidence, such as evidence from the Cancer Gene Census for the association between PTEN and cutaneous melanoma, will bring up a searchable list of publications.
-
With this latest release, we are re-introducing the variant-based target-disease evidence source from Uniprot. It complements the curated associations in the ClinVar evidence set with an additional 7127 unique variants, as well as further curated information.
-
We have introduced a completely new design of the evidence pages, and included clinical signs and symptoms associated with diseases. More information is available in the beta release blog post.
A redesigned infrastructure
The technical stack for the next-generation Open Targets Platform has been completely overhauled. This has enabled us to implement an entirely new Scala/Spark ETL pipeline, GraphQL API, and React web application, all using powerful, leading-edge technologies.
The user interface has been both redesigned and completely reimplemented in order to maximise the impact of casual findings. The underlying algorithms provide flexible, on-the-fly calculations of association scores, and as such, unblock more user-driven queries.
This also enables much faster development and deployment strategies, facilitating the implementation of custom instances of the Platform. However, please note that the infrastructure to create self-hosted versions of the next-generation Platform is not yet available. To know when the infrastructure is available for private instances, join the Open Targets Community.
More data access options
Depending on the complexity of the query and the user’s programmatic skills, we have a range of ways to access our data.
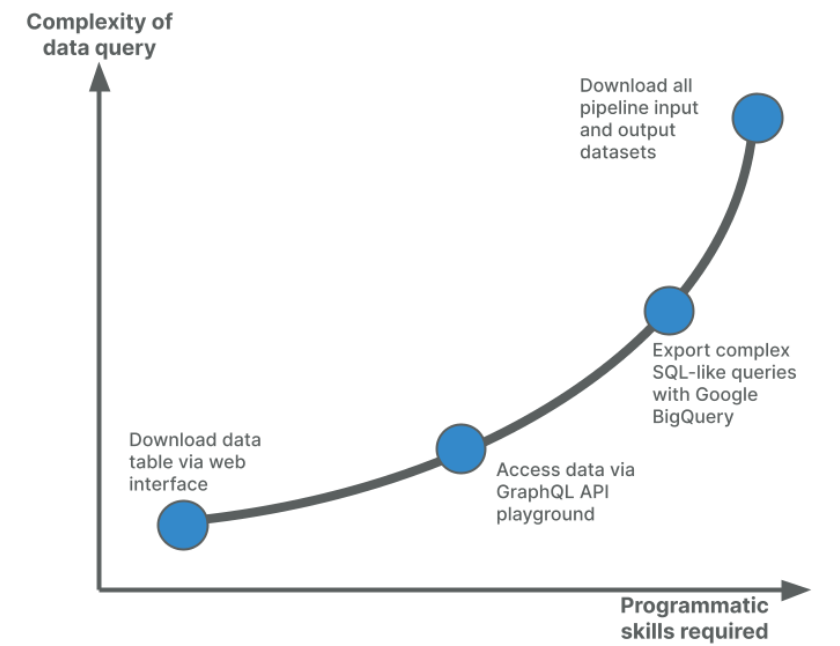
Web application
For single entities or target disease associations, users can use the search function on our web interface, and navigate to entity pages, associations pages, or evidence pages. Data tables and visualisations can be downloaded in multiple formats.
The web application is available at platform.opentargets.org.
GraphQL API
Our next-generation Platform comes with a GraphQL API. It provides a friendly, language-agnostic access point to the information displayed in the web application. The GraphQL playground contains a schema to help you construct tailored queries.
Users of Open Targets Genetics will be familiar with this API, and you can see our blog post on the topic to get an overview of how it works.
However, the API only supports queries for a single entity or association. More complex queries should make use of our data downloads or Google BigQuery.
Google BigQuery and data downloads
Google BigQuery allows you to run asynchronous SQL queries using Google Cloud’s infrastructure, and export the results or copy them into Google Cloud buckets.
We also provide downloads for all data files generated by our ETL pipelines, with more than 20 datasets available. These data downloads contain information on all targets, diseases/phenotypes, and drugs, allowing users to explore specific datasets and integrate them into their own pipelines. Our new documentation space contains example scripts in Python and R so that you can easily get started with using our data downloads.
For more information, take a look at the Platform documentation.
What’s next?
You need more!?
Well, once our team pauses for a well-deserved celebration, we’ll keep working on improving the Platform. In particular, we will focus on enhancing private instances of the Platform, and incorporating ever more data, including negative evidence such as reasons behind terminated clinical trials.
What do you think of the next-generation Platform? Are there any other features you’d like to see? Let us know on the new Open Targets Community!
This post was updated on 01.03.22 to corrected the reported number of associations.